July 2018 News Roundup
This month’s episode is a roundup of news from a variety of sources covering three main topics:
- BI / Dataviz Tools
- Databases and Platforms
- Tools and Frameworks
Note: Most of the text extracts below are direct quotations from new sources cited in the source list at the bottom of these show notes. This episode is a compilation from those sources.
BI / Dataviz Tools
PowerBI enhancements (7/12/18)
- Microsoft has updated its Power BI analytics service in an effort to expand data prep capabilities and unify data analytics across platforms.
- “Using the Power Query experience familiar to millions of Power BI Desktop and Excel users, business analysts can ingest, transform, integrate and enrich big data directly in the Power BI web service – including data from a large and growing set of supported on-premises and cloud-based data sources, such as Dynamics 365, Salesforce, Azure SQL Data Warehouse, Excel and SharePoint,” the post reads.
- Power BI now supports data in Azure Data Lake Storage, and integrates with SQL Server Analysis Services and SQL Server Reporting Services.
- Microsoft today announced the general availability of Visio Visual for Power BI. Based on the feedback collected from the customers during the preview period, Microsoft has made the following changes to the Visio Visual:
- Support for Power BI Mobile app
- The ability to change the diagram link embedded earlier and to copy an embedded link to the clipboard
- Configurable auto-zoom settings that can be turned on and off
- Support for complex diagrams using layers
- Overall performance improvements
Tableau acquires Empirical Systems
- Tableau last month announced the acquisition of Empirical Systems, an artificial intelligence (AI) startup with an automated discovery and analysis engine designed to spot influencers, key drivers, and exceptions in data.
Looker Enhances Data Science Capability with Integration for Google Cloud BigQuery ML
- With Looker and BQML, data teams can now save time and eliminate unnecessary processes by creating machine learning (ML) models directly in Google BigQuery via Looker – without the need to transfer data into additional ML tools. BQML predictive functionality will also be integrated into new or existing Looker Blocks allowing users to surface predictive measures in dashboards and applications.
DBs and Platforms
MemSQL Unveil Significant Update to Database for Real-time Modern Applications and Analytical Systems (Version 6.5 released)
- Queries are now up to four times faster than the previous MemSQL version (which was already 10x faster than legacy database providers), enabling insights in milliseconds across billions of rows.
- New automated workload optimization capabilities provide a consistent database response under ultra-high concurrency without the need for manual tuning or specialized DBA resources.
- Additions to the MemSQL industry-leading “transform-as-you-ingest” capabilities allow customers to use stored procedures for in-database transformations to easily build real-time data pipelines.
- Resource optimization improvements for multi-tenant deployments deliver greater control and scalability for varied database sizes whether on-premises or in the cloud.
Hortonworks Data Platform 3.0
- Even a Hadoop stalwart such as Hortonworks Inc. sees the writing on the wall, which is why, in its recent 3.0 release, it emphasized heterogeneous object storage. The new Hortonworks Data Platform 3.0 supports data storage in all of the major public-cloud object stores, including Amazon S3, Azure Storage Blob, Azure Data Lake, Google Cloud Storage and AWS Elastic MapReduce File System.
- HDP’s latest storage enhancements include a consistency layer, NameNode enhancements to support scale-out persistence of billions of files with lower storage overhead, and storage-efficiency enhancements such as support for erasure coding across heterogeneous volumes. HDP workloads access non-HDFS cloud storage environments via the Hadoop Compatible File System API.
- My thoughts: Are Hadoop and HDFS Dying???
- As we are heading into the fourth industrial revolution, HDP 3.0 is a giant leap for the Big Data ecosystem, with major changes across the stack and expanded eco-system (Deep Learning and 3rd Party Dockerized Apps). HDP 3.0 can be deployed both on-premise and in the major cloud platforms – AWS, Microsoft Azure, and Google Cloud. Many of the HDP 3.0 new features are based on Apache Hadoop 3.1 and include containerization, GPU support, Erasure Coding and Namenode Federation. In order to provide a Trusted Data Lake, we are installing Apache Ranger and Apache Atlas by default with HDP 3.0. In order to streamline the stack, we have removed components such as Apache Falcon, Apache Mahout, Apache Flume, and Apache Hue, and absorbed Apache Slider functionalities into Apache YARN.
Tools and Frameworks
Python 3.7.0 is now available
- Data classes that reduce boilerplate when working with data in classes.
- A potentially backward-incompatible change involving the handling of exceptions in generators.
- A “development mode” for the interpreter.
- Nanosecond-resolution time objects.
- UTF-8 mode that uses UTF-8 encoding by default in the environment.
- A new built-in for triggering the debugger.
- Easier access to debuggers through a new breakpoint() built-in
- Simple class creation using data classes
- Customized access to module attributes
- Improved support for type hinting
- Higher precision timing functions
- More importantly, Python 3.7 is fast.
- Each new release of Python comes with a set of optimizations. In Python 3.7, there are some significant speed-ups, including:
- There is less overhead in calling many methods in the standard library.
- Method calls are up to 20% faster in general.
- The startup time of Python itself is reduced by 10-30%.
- Importing typing is 7 times faster.
- Each new release of Python comes with a set of optimizations. In Python 3.7, there are some significant speed-ups, including:
- You can easily get an idea of how much time the imports in your script takes, using -X importtime:
Apache OpenNLP 1.9.0 released
- The Apache OpenNLP team is pleased to announce the release of Apache OpenNLP 1.9.0.
- The Apache OpenNLP library is a machine learning based toolkit for the processing of natural language text.
- It supports the most common NLP tasks, such as tokenization, sentence segmentation, part-of-speech tagging, named entity extraction, chunking, parsing, and coreference resolution.
- Apache OpenNLP 1.9.0 binary and source distributions are available for download from our download page: download page
- The OpenNLP library is distributed by Maven Central as well. See the Maven Dependency page for more details: Maven Dependency
- What’s new in Apache OpenNLP 1.9.0
- This release introduces new features, improvements and bug fixes. Java 1.8 and Maven 3.3.9 are required.
- Additionally the release contains the following changes:
- Brat Document Parser should support name type filters
- Brat format support fails on multi fragment annotations
- Remove MD5 hashes from Release process
- Use String[] instead of StringList in LanguageModel API
- BRAT Annotator service Fails to start
- Token model creation fails without at least one <SPLIT> tag
- Update Penn Treebank URL
- Explain the new format of feature generator XML config
- Unify code to sum up input context features
- FeatureGeneratorUtil can recognize Japanese Hiragana and Katakana letters
TensorFlow 1.9.0
- Updated docs for tf.keras: New Keras-based get started and programmers guide page.
- Update tf.keras to the Keras 2.1.6 API.
- Added tf.keras.layers.CuDNNGRU and tf.keras.layers.CuDNNLSTM layers. Try it.
- Adding support of core feature columns and losses to gradient boosted trees estimators.
- The python interface for the TFLite Optimizing Converter has been expanded, and the command line interface (AKA: toco, tflite_convert) is once again included in the standard pip installation.
- Improved data-loading and text processing with:
- Added experimental support for new pre-made Estimators:
- The distributions.Bijector API supports broadcasting for Bijectors with new API changes.
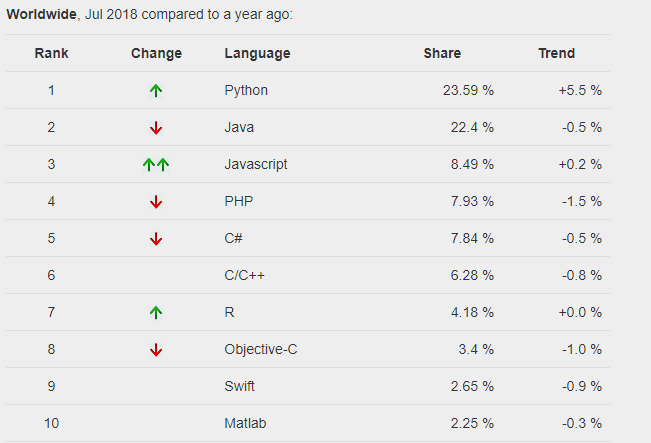
PYPL Language Rankings: Python ranks #1, R at #7 in popularity
- The new PYPL Popularity of Programming Languages (June 2018) index ranks Python at #1 and R at #7.
Music:
Deep Sky Blue by Graphiqs Groove via FreeMusicArchive.org
Sources:
- https://www.techrepublic.com/article/microsoft-power-bi-expansion-aims-to-help-analysts-leverage-business-data-more-easily/
- https://mspoweruser.com/visio-visual-for-power-bi-now-available-for-everyone/
- https://appsource.microsoft.com/en-us/product/office/WA104381132?src=office&corrid=5ebc6738-bf41-4363-bfc9-d46077451402&omexanonuid=19a90565-f1ed-4800-a00b-8ed084f0fe61
- https://www.zdnet.com/article/tableau-takes-next-steps-toward-smart-analytics/
- https://insidebigdata.com/2018/07/29/memsql-unveil-significant-update-database-real-time-modern-applications-analytical-systems/
- http://blog.revolutionanalytics.com/2018/07/ai-roundup-july-2018.html
- https://pythoninsider.blogspot.com/2018/06/python-3.html
- https://www.python.org/downloads/release/python-370/
- https://www.infoworld.com/article/3252852/python/whats-new-in-python-37.html
- https://realpython.com/python37-new-features/
- http://blog.revolutionanalytics.com/2018/06/pypl-programming-language-trends.html
- http://pypl.github.io/PYPL.html
- https://insidebigdata.com/2018/07/29/looker-enhances-data-science-capability-integration-google-cloud-bigquery-ml/
- https://github.com/tensorflow/tensorflow/releases/tag/v1.9.0
- https://opennlp.apache.org/news/release-190.html
- https://siliconangle.com/2018/07/09/hadoops-star-dims-era-cloud-object-data-storage-stream-computing/
- https://hortonworks.com/blog/announcing-general-availability-hortonworks-data-platform-3-0-0-ambari-2-7-0-smartsense-1-5-0/
Podcast: Play in new window | Download