Where did graphs come from? (Graph Theory History)
In its simplest form, Graph Theory defines a graph as a construct made up of vertices, nodes, or points which are connected by edges, arcs, or lines.1 The connections may be directed, indicating a direction from one node to another, or undirected. Properties are attributes associated with nodes that describe the node in some detail.

Graph theory is applied in many disciplines from linguistics to computer science, physics, and chemistry. Popular uses will be discussed below. Leonhard Euler published “Seven Bridges of Königsberg” in 1736; this is commonly attributed as the first paper about graph theory. James Joseph Sylvester published a paper in 1878 where the term “graph” was first introduced. The first textbook was later published in 1936.1
There are various algorithms that define how to best traverse through a graph from one node to another based on the edges between them.
So what…I’ve never used a Graph Database.
- Have you ever used Google? If so, then you’ve used the most well-known implementation of a graph database in recent times.
- Google, Faceook, and LinkedIn all use proprietary forms of graph databases to underpin parts of their websites.
How Google uses Graphs
In the original 1998 academic paper that Sergey Brin and Lawrence Page wrote, they described PageRank, the graph portion of their first implementation of Google.
Basically, all webpages are treated as nodes. The hyperlinks between the pages are edges, and an algorithm assigns a weight to the credibility of each page. The more links a page has to credible sources, the higher that page’s credibility becomes. A search is a) broken down into a series of words, b) used to find pages that most closely correlate to those words, and c) page results are ranked according to their credibility, or PageRank.
As of mid-2016, the size of Google’s index as 130 trillion. Google has a nice infographic site on how search works here.

What’s so good about a graph database?
For use cases involving complex relationships and traversal of these, graphs make great choices. They can provide10:
- Flexible and agile – a graph database should closely match the structure of the data it uses. This allows developers to start work sooner without the added complexity of mapping data across tables. Neo4J call this ‘whiteboard friendliness’ – meaning what you draw as the design on your whiteboard is how the data is stored in your database.

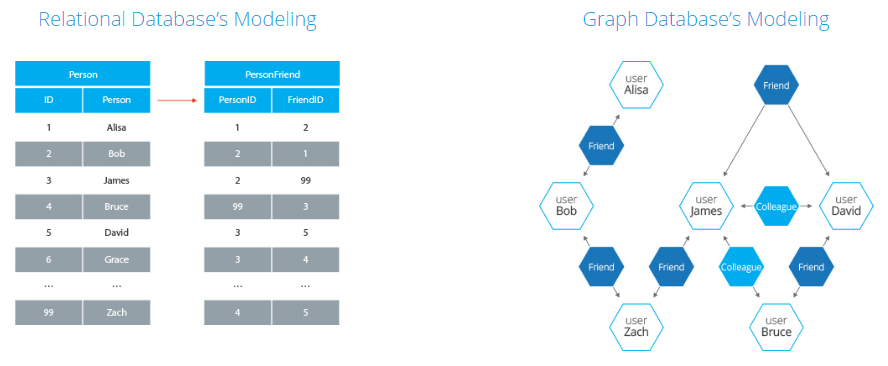
- Greater performance – compared to NoSQL stores or relational databases, graph databases offer much faster access to complex connected data, mainly as they lack expensive ‘join’ operations. In one example, a graph database was 1000x faster than a relational database when working with a query depth of four.

[Caveat: I did not perform this comparison, but I imagine a properly indexed instance of an Oracle database could complete this query in a decent amount of time, perhaps not as fast as Neo4j, but I bet it would at least finish the query.]

- Lower latency – users of graph databases experience lower levels of latency. As the nodes and links ‘point’ to one another, millions of related records can be traversed per second and query response time remains constant irrespective of the overall database size.

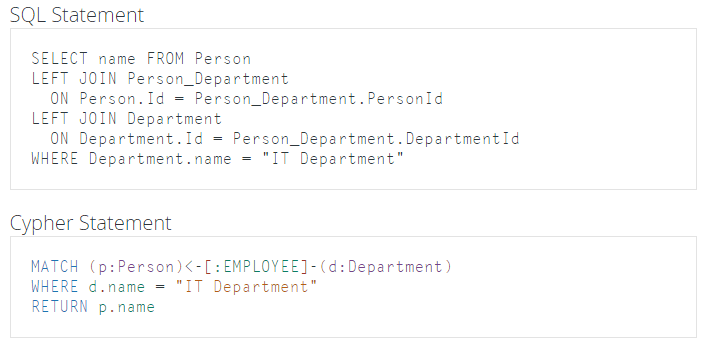
– Sample graph query
- Good for semi-structured data – graph databases are schema free, meaning patchy data, or data with exceptional attributes, don’t pose a structural problem.
(All of these bullets above are from https://cambridge-intelligence.com/keylines/graph-databases-data-visualization/)
When should you use a graph database?
The most popular and hottest use cases of graph DBs at the moment are:
- Social network connections
- Credit card fraud analysis
- Recommendation engines
- Master Data Management (MDM) – i.e., 360-degree view of customer
- Logistics planning for transportation, traffic, shipping, etc.
- Computer/telecom network planning and analysis
These boil down to the following uses10:
- Path finding: Their traversal efficiency make graph databases an effective path-finding mechanism. Links can be weighted, or assigned relative distances or times, to ascertain the shortest and most efficient routes between two nodes in a network.
- Mapping dependencies: networks of computers and hardware can be modeled as graphs to find components with many dependents that may be potential weak points or vulnerabilities. Other dependency networks, for example corporate or investment structures can be mapped in a similar manner.
- Communications: Communications between people can be stored as graphs. Applying network analysis measures can help find influential individuals.
- All of these bullets above are from https://cambridge-intelligence.com/keylines/graph-databases-data-visualization/
The Panama Papers13,14
In 2016 11.5 million documents comprising 2.6TB of information were leaked from a Panama law firm (Mossack Fonseca). These documents were scanned and processed into the Neo4j graph database where investigative journalist used graph visualizations to uncover hidden insights and relationships that would have otherwise been missed.


See the articles at Neo4J for more information on how this information was analyzed.
What graph databases should I use9?
Neo4j is far and away the most popular graph database. Neo4j and several of the other top graph DBs are all open source. Below is the trend of popularity for these databases from DB-engines.com. Neo4j is first with a score of 36.27, followed by OrientDB (5.87) and Titan (5.08).
|
Rank |
DBMS |
Database Model |
Score |
||||
|
Feb 2017 |
Jan 2017 |
Feb 2016 |
Feb 2017 |
Jan 2017 |
Feb 2016 |
||
|
1. |
1. |
1. |
36.27 |
+0.00 |
+3.98 |
||
|
2. |
2. |
2. |
|
Multi-model
|
5.87 |
+0.06 |
-0.55 |
|
3. |
3. |
3. |
5.08 |
-0.42 |
-0.27 |

Tips for converting from a RDBMS to Graph (from Neo4j)12:

- Each entity table is represented by a label on nodes
- Each row in a entity table is a node
- Columns on those tables become node properties.
- Remove technical primary keys, keep business primary keys
- Add unique constraints for business primary keys, add indexes for frequent lookup attributes
- Replace foreign keys with relationships to the other table, remove them afterwards
- Remove data with default values, no need to store those
- Data in tables that is denormalized and duplicated might have to be pulled out into separate nodes to get a cleaner model.
- Indexed column names, might indicate an array property (like email1, email2, email3)
- Join tables are transformed into relationships, columns on those tables become relationship properties
Music:
Music for today’s podcast is Cyanos by Graphiqs Groove via FreeMusicArchive.org.
Sources:
- https://en.wikipedia.org/wiki/Graph_theory
- https://en.wikipedia.org/wiki/Graph_database
- https://blogs.cornell.edu/info2040/2011/09/20/pagerank-backbone-of-google/
- http://ilpubs.stanford.edu:8090/361/1/1998-8.pdf
- https://neo4j.com/why-graph-databases/
- https://en.wikipedia.org/wiki/Neo4j
- https://academy.datastax.com/resources/getting-started-graph-databases
- http://www.predictiveanalyticstoday.com/top-graph-databases/
- http://db-engines.com/en/ranking/graph+dbms
- https://cambridge-intelligence.com/keylines/graph-databases-data-visualization/
- http://bitnine.net/rdbms-vs-graph-db/?ckattempt=2
- https://neo4j.com/developer/graph-db-vs-rdbms/
- https://neo4j.com/blog/icij-neo4j-unravel-panama-papers/
- https://neo4j.com/blog/analyzing-panama-papers-neo4j/
Podcast: Play in new window | Download